There are over 2.5 quintillion bytes of data created every single day. But raw data alone isn’t helpful for businesses — in fact, too much unfiltered data can actually be counterproductive for business decisions. Data pipeline tools exist to help businesses extract, transform, and load (ETL) relevant data in a way that guides decision makers and drives business insights.

The most competitive data-driven companies rely on AI pipelines and unstructured data processing to help them synthesize massive amounts of data from a variety of sources. Data pipeline tools give teams scalability, flexibility, and reliability in how they manage their data.
In this guide, we’ll compare the best data pipeline tools available in 2026 to help you find the right fit for your team.
What Are Data Pipeline Tools?
Data pipeline tools give companies the power to collect, clean, and transform data from a variety of sources (databases, APIs, etc.) into their data warehouse, data lake, or analytics platform.
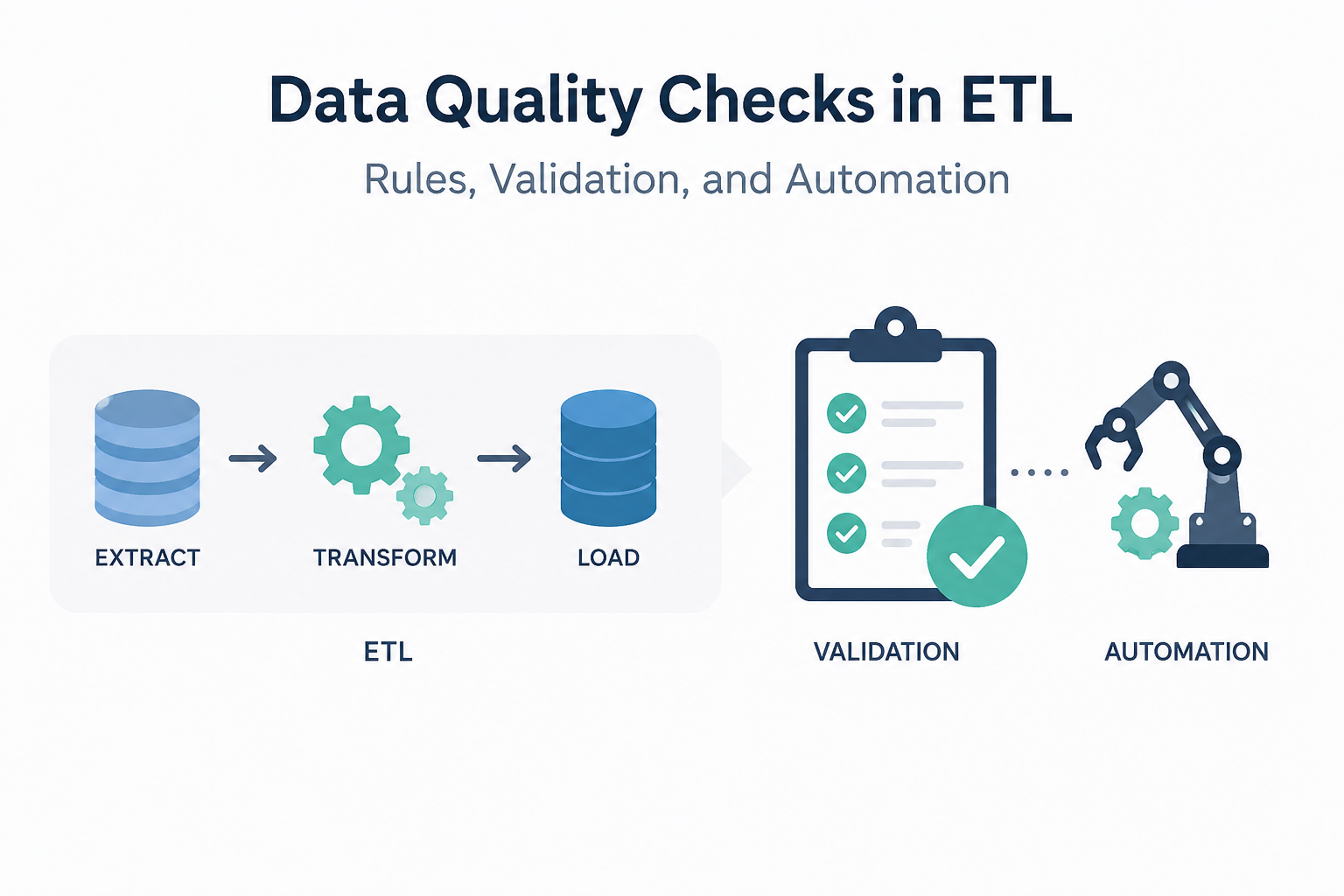
This process is usually referred to as ETL: Extract, Transform, Load.
-
- Extract Gather data from a variety of sources like APIs, databases, files, open source, etc.
-
- Transform Validate, clean, and enrich the data; then, structure and format it
-
- Load Deliver structured data to a specific destination
Some data engineering tools follow a slightly different process in which they extract, load, and then transform data (ELT).
ETL tools in 2026 ensure that your data is accurate, up-to-date, secure, and cleanly formatted to improve analytics and drive business decisions.
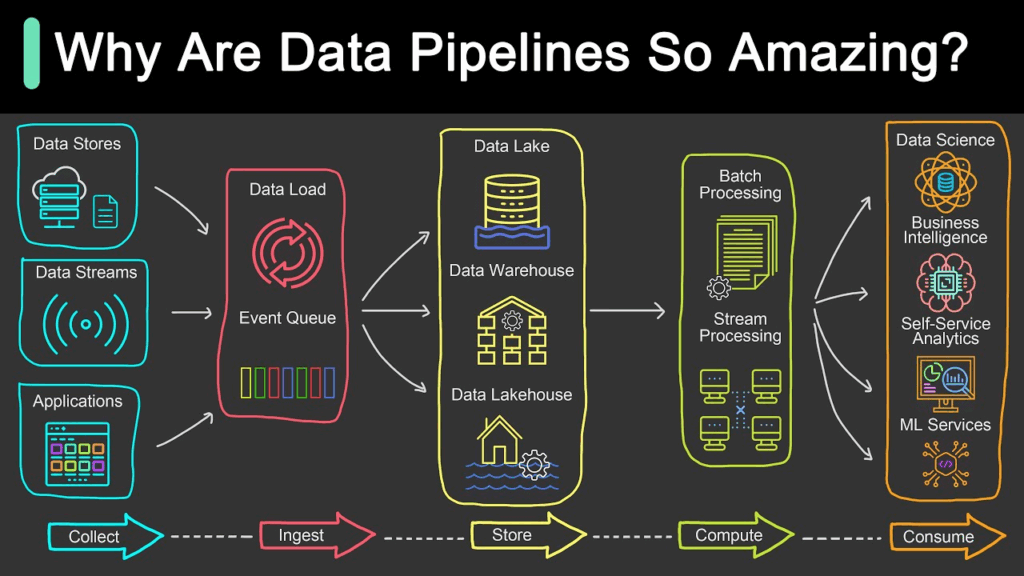
They automate the flow and structure of massive amounts of data so that teams can spend their time analyzing and gaining insight from it, rather than managing it.
Types of Data Pipeline Tools: Batch vs. Real-time
All data pipeline tools exist to make data collection, management, and analysis easier for teams, but not all are created with the same features. There are two main types of data pipeline tools:
-
- Batch data pipeline tools extract data at scheduled times (e.g. hourly, daily). They do not perform real-time, continuous data ETL.
-
- Real-time data pipeline tools, on the other hand, process newly-generated data on a continuous basis. Real-time data pipeline tools allow teams to make lightning-fast decisions that move with their market.
While many companies prefer the immediate data updates offered by streaming data tools, some specific industries (e.g., finance and healthcare) prioritize data auditability and compliance over constant ETL. Batch pipeline tools offer an advantage in these markets.
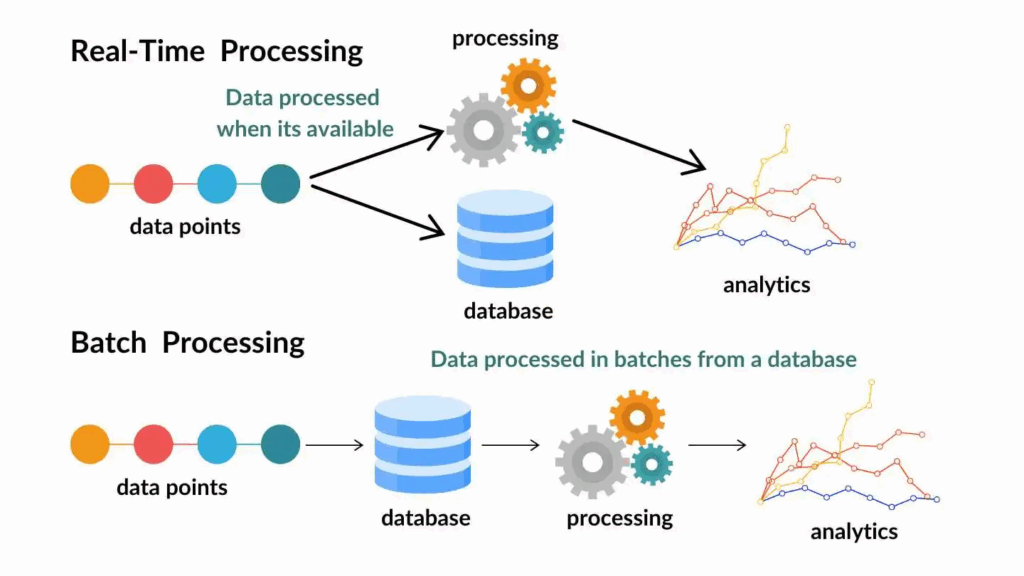
Both types of data integration tools automate the way businesses move, organize, and analyze data for elevated insights and faster, more informed decision-making.
Types of Data Pipelines: Structured vs. Unstructured
There are two kinds of data pipelines that teams rely on: structured and unstructured.
-
- Structured data pipelines handle data that’s already formatted (e.g., tables, spreadsheets, SQL databases). This is the more traditional pipeline model and, for a long time, was considered easier to process and analyze.
-
- Unstructured data pipelines, on the other hand, can also process data in non-traditional formats like video, text, images, PDFs, and more.
Most organizations report that both types of data pipelines are valuable to their decision-making process.
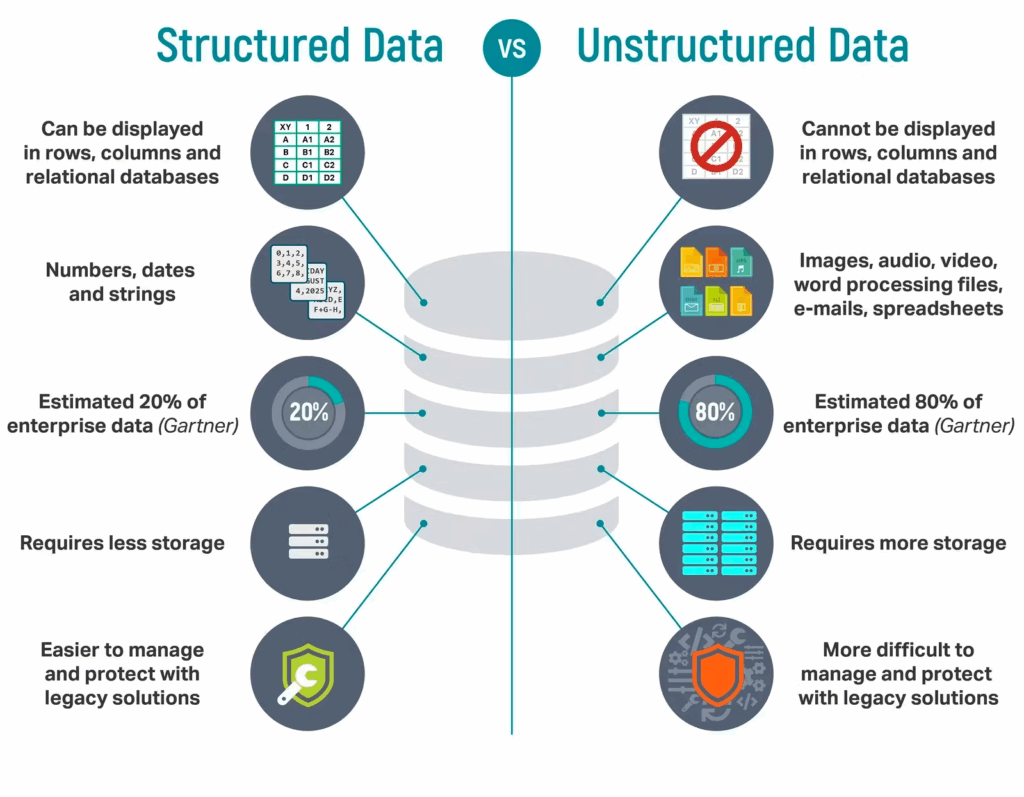
Until recently, unstructured pipelines were regarded as more complex, relatively inaccessible, and sometimes even unnecessary for many teams. However, with advancements in AI and machine learning, unstructured data pipelines can offer a serious competitive advantage for teams that want to add more context and depth to their pipelines. In fact, Gartner reports that 80 – 90% of enterprise data is unstructured.
Key Capabilities in Data Pipeline Tools
Regardless of the unique features offered by different platforms, any data pipeline tool you choose should help your team automate, scale, and verify the data it uses to make business decisions.
-
- Automation All ETL pipeline tools in 2026 should automate data flow tasks like scheduling and transformation. They should reduce your team’s manual resources, decrease or eliminate data errors and oversights, and ensure consistent data availability and analysis.
-
- Scalability Your data pipeline tool needs to be able to keep up with the ever-growing pool of data available to organizations. The tool should be able to grow with your team and its data without major infrastructure disruption.
-
- Data Reliability Data is useless if it’s not accurate and on time. Data pipeline tools can seamlessly handle data monitoring, logging, and validation, and alert teams when errors arise.
Data pipeline tools optimize data efficiency, regardless of the size of your organization or the volume of data it ingests.
Top Data Pipeline Tools 2026
There are an overwhelming number of data pipeline tools to choose from, each with their own pros and cons.
Before jumping into the details of some of the best options, keep in mind the following criteria as you evaluate the best ETL tool for your team in 2026:
-
- Ease-of-Use Low-code and no-code platforms like Dagflux and Hevo give teams a fast and easy way to build pipelines and analyze their data quickly without engineering support.
-
- Pricing Model Pay careful attention to the pricing model attached to the tool you choose. Some offer monthly subscription plans, but others charge based on usage — costs can get out of control quickly as the volume of your data grows.
-
- Real-Time Capabilities Modern data-driven teams often require access to the most up-to-date data to make informed decisions. Look for a real-time data pipeline tool to give your team access to the most recent insights and market trends.
-
- Best Use Case There are very few “bad” data pipeline tools; there are, however, badly-matched ones. Some tools are best suited for teams with significant data engineering support, while others are perfect for non-technical teams.
-
- Scalability The data integration tool you choose should be able to scale with your team and the amount of data it ingests, without exorbitant price increases and/or performance failure.
With those criteria in mind, here are 10 of the best data pipeline platforms to consider for your team.

1. Dagflux
Dagflux is a modern unstructured data pipeline platform that’s built for AI workflows, LLM pipelines, and scalable data ingestion. Its AI-driven pipeline architecture gives users the ability to enter plain-English directives for how data should be organized and formatted:
-
- “Filter for the last 30 days.”
-
- “Show me customers and their orders.”
-
- “Find top 10 users by revenue.”
Despite the simple, user-friendly interface, Dagflux is capable of handling massive volumes of complex data, delivering the exact insights users need in a clean format.
Key Features
-
- Automated SQL and Python transformation logic
-
- Supports structured and unstructured data
-
- End-to-end workflow
-
- AI-ready pipeline architecture
-
- Highly scalable infrastructure
Among its competitors, Dagflux stands out in 2026 for the way it balances its powerful ETL capability with data accessibility via visual, drag-and-drop workflows — absolutely no coding required.
Best for: AI startups, SaaS platforms, data-heavy products

2. Apache Airflow
Apache Airflow is not technically an ETL tool; instead, it’s an open-source workflow orchestration and scheduling tool.
Unlike no-code-required Dagflux, Apache Airflow is a code-first platform that’s a good fit for engineering-heavy teams.
Key Features
-
- Python-based DAGs (Directed Acrylic Graphs)
-
- Highly customizable
-
- Powerful orchestration capabilities
Teams with robust engineering resources appreciate the way Apache Airflow gives them ultimate visibility into where their pipelines are working and where they’re failing. As the most widely-used open-source data pipeline scheduling platform, there is a deep network of available integrations.
It’s worth reiterating, though, that Airflow is not suited for teams with limited or even basic coding capability. Set-up is complex and can be overwhelming — the same goes for scalability. It will also require a separate ETL platform and will not work for teams that are looking primarily for significant data transformation.
Best for: teams with ample engineering support.
3. Fivetran
Fivetran is a no-code, fully-managed ELT tool that’s quick to set up and requires minimal maintenance.
Key Features
-
- 700+ pre-built connectors
-
- Seamless integration with all major data warehouses, including Snowflake, BigQuery, and Azure Synapse
-
- Strong compliance and security features
It’s worth noting that Fivetran is one of the most expensive ELT platforms available, and pricing depends on your monthly active rows (MAR); the higher your volume of data, the more you’ll spend. It’s also not the most flexible option on our list, especially for teams that require custom transformation logic or the ability to connect to lesser-known source connectors.
Best for: enterprise companies that can afford the higher price tag; teams that want fast setup and minimal maintenance
4. Stitch
Stitch is another good choice for data teams that need fast and easy set up with straightforward ETL workflows.
This platform is truthfully at its best in the EL realm — some users report that its data transformation capabilities can be a bit basic and don’t leave a lot of room for flexibility.
Key Features
-
- 130+ connectors
-
- Easy setup
-
- Integrates with open-source Singer.io
It also offers high-level data security and compliance right out of the box.
Its price tag reflects its simplicity, coming in at one of the more affordable options on our list. That being said, its customer support capabilities can be limited, with some users reporting that higher-complexity issues can be challenging to resolve in a timely manner.
Best for: startups and small businesses
5. Talend
Talend is one of the best batch data pipeline tools. It prioritizes compliance and governance features, making it an excellent choice for teams who require strong auditability.
Key Features
-
- Impressive data quality and governance
-
- Hybrid support (on-premises + cloud)
-
- Drag-and-drop workflows
Despite its easy interface, this platform has a steep learning curve; it’s a good option for enterprise organizations that have dedicated IT departments available to customize their data pipeline workflows.
Best for: enterprise organizations with complex data requirements and/or compliance concerns that can provide engineering resources for setup and management
6. Matillion
Matillion is a cloud-native ETL that leverages the power of your data warehouse to perform complex transformations using a visual, low-code interface.
Key Features
-
- Integrates with Snowflake, BigQuery, and Redshift
-
- Builds visual pipelines
-
- Offers business intelligence capabilities
Some users report that support can feel limited, with most opportunities for troubleshooting directed to published help articles or ticket submission. Unlike many of the other options on our list, Matillion offers hourly pricing after a 14-day free trial.
Best for: teams with SQL expertise
7. Hevo Data
Hevo Data is a no-code pipeline platform with real-time streaming capabilities.
Key Features
-
- Automatic schema detection
-
- Straightforward user interface with drag-and-drop data pipelines
-
- 150+ connectors
In addition to ETL capabilities, the platform also supports reverse ETL, meaning data can be moved in both directions. Users also appreciate Hevo’s 24/7 support availability via live chat with an SLA.
Best for: teams that want easy and fast onboarding with real-time updates
8. AWS Glue
AWS Glue is a serverless ETL that offers deep integration with the AWS ecosystem.
Key Features
-
- Batch and streaming data processing
-
- Automated schema detection
-
- Serverless technology for scalability
The platform supports Python (Ray) and Spark for large volumes of data, while requiring teams to only pay for what they use. That being said, teams that process massive amounts of data report that the price tag can quickly grow out of control. Some users also report that the learning curve is steep.
Best for: organizations that are already in the AWS ecosystem
9. Google Cloud Dataflow
Google Cloud Dataflow is built on Apache Beam and offers both real-time streaming and batch data processing.
Key Features
-
- Pre-built pipeline templates for common ETL patterns
-
- Fully managed by Google
-
- Auto-scaling infrastructure
Similar to AWS Glue, Google Cloud Dataflow is a great option for those already working within the Google Cloud ecosystem — on the flip side, it can be very limiting for those who need more flexibility.
Best for: real-time analytics for large volumes of data
10. Azure Data Factory
Azure Data Factory offers hybrid data pipeline support with Microsoft ecosystem integration. This platform can handle ETL, ELT, and reverse ELT.
Key Features
-
- Visual pipelines
-
- Integration with Azure and 80+ data sources, including SQL and NoSQL databases
-
- No-code, low-code, and coding options to meet a variety of team capabilities
Microsoft prioritizes data security and compliance with features like data encryption and role-based access control. It also offers a variety of support options, including both free resources and paid levels of 24/7 support that provide faster response times.
Best for: organizations already using Microsoft Azure
Top Tools: A Side-by-Side
Here’s a look at our top 10 data pipeline tools in table format.
| Ease of Use | Pricing Model | Real-Time Capability | Best Use Case | Scalability | |
| Dagflux | Easy | Custom based on usage | Real-time streaming | Real-time, no-code data pipelines for analytics | High |
| Apache Airflow | Moderate – Hard (requires technical setup) | Open-source | Limited (better for batch use) | Scheduled ETL tasks & workflow orchestration | High |
| Fivetran | Easy | Subscription model (per connector/usage based) | Near real-time | SaaS data ingestion, automating ELT pipelines | High |
| Stitch | Easy | Tiered subscription model (MAR) | Near real-time (batch micro-syncing) | Small and mid-size teams, light load ELT with no code required | Moderate |
| Talend | Moderate | Subscription model | Supports real-time and batch | Enterprise ETL with attention to compliance, complex and high-volume data loads | High |
| Matillion | Moderate | Subscription model (cloud-based) | Near real-time | Cloud-based data warehouse transformations, machine learning at scale for complex data pipelines | High |
| Hevo Data | Easy | Subscription model (event/volume-based) | Real-time streaming | No-code, real-time pipelines, ELT from SaaS platforms and databases into data warehouses | High |
| AWS Glue | Moderate (requires AWS knowledge) | Pay-as-you-go | Supports real-time streaming | Serverless ETL in AWS | High |
| Google Cloud Dataflow | Very Hard (requires intense engineering support) | Pay-as-you-go | Real-time streaming via Apache Beam | Unified stream and batch processing at scale, real-time analytics, large-scale transformations | High |
| Azure Data Factory | Moderate | Pay-as-you-go | Near real-time (not true streaming) | Hybrid/cloud ETL/ELT orchestration | High |
It’s important to consider each criteria based on its relevance to your team; some teams need to prioritize budget above all other factors, while others will pay any price for a tool that’s ready to use right out of the box.
How to Choose the Right Data Pipeline Tool
Each data pipeline tool comes with its own pros and cons, and what’s right for one team may be counterproductive for another. Consider the following factors as you evaluate which option is best for your team.
-
- Company Size The data pipeline needs of a startup differ significantly from those of an enterprise organization. Small teams can easily become overwhelmed with too much to evaluate and manage — in many cases, too many features can be more detrimental than a small subset of simple but effective ones.
-
- Data Complexity Consider the volume, velocity, and variety of your data. Smaller subsets of structured data may do well with a lighter-weight, no-code tool that delivers streamlined insights. Organizations that rely on multiple data sources, unstructured data, or other more complex inputs may need to opt for a more intricate data pipeline tool.
-
- Budget There are platforms available to fit just about every budget; even a very affordable tool can have a huge impact on the data insights and analysis available to your team. As part of your budget evaluation, pay careful attention to the pricing structure of the tools you’re considering; some remain static while others are dynamic based on use and scaling.
No-Code vs. Engineering Heavy Tools
It’s crucial that you have a deep understanding of the engineering resources available to onboard and maintain your data pipeline tool.
While many teams would ultimately love the flexibility and customization capabilities of a code-heavy platform, the truth is that none of those features can be optimized without the right people on your team to develop them.

Low-code and no-code platforms exist to help teams with little technical support get the most out of their data without the need for complicated integrations. They’re a great option for teams with few engineering resources, or those who want to get started quickly with little maintenance.
Engineering-heavy tools, on the other hand, require more technical setup and ongoing maintenance — but provide teams with more flexibility, customization, and control in return.
There are a few other specific considerations to keep in mind as you evaluate your options.
-
- Does the tool support your existing data sources and destinations?
-
- Is it scalable and able to grow with your team, without runaway costs and/or performance disruption?
-
- What is the advertised uptime? Look for platforms that ensure 99% or better.
-
- What does the platform’s data monitoring/alert system look like? Are logs detailed and transparent? How and when will you be notified when pipelines fail?
-
- Are security and compliance features built in? Look for tools that provide end-to-end encryption, as well as adherence to any industry specific governance required in your field (e.g. HIPPA, GDPR, etc.).
-
- Do you need real-time streaming capability, batch processing, or a hybrid approach?
-
- How and when will pricing change over time or based on usage?
-
- How vast is its connector library?
-
- Does the tool offer automated schema management? A solid data pipeline tool should be able to identify changes in source data and update within your destination automatically.
The bottom line: choose a tool that gives you visibility into the data your team uses on a day-to-day basis. It should empower you to process and analyze the data points that give you the most leverage.
Trends in Data Pipelines for 2026
Given how rapidly new data generates, teams that want to remain competitive need to stay ahead of the curve when it comes to data pipelines in 2026.
Here are the trends giving teams an edge:
-
- AI-native Pipelines Platforms like Dagflux put AI in the driver’s seat, rather than an add-on or nice-to-have. An AI-native pipeline improves its performance with each ELT — the more you use it, the better it gets.
AI-forward platforms generate sophisticated business insights automatically, without the need for complex code or engineering. They also give users the ability to add context and nuance to its tasks in a way that traditional systems can’t handle.
-
- Real-time data processing While batch processing can be a good model for select industries and organizations, most companies absolutely must have up-to-the-minute access to the massive volume of data available to them.
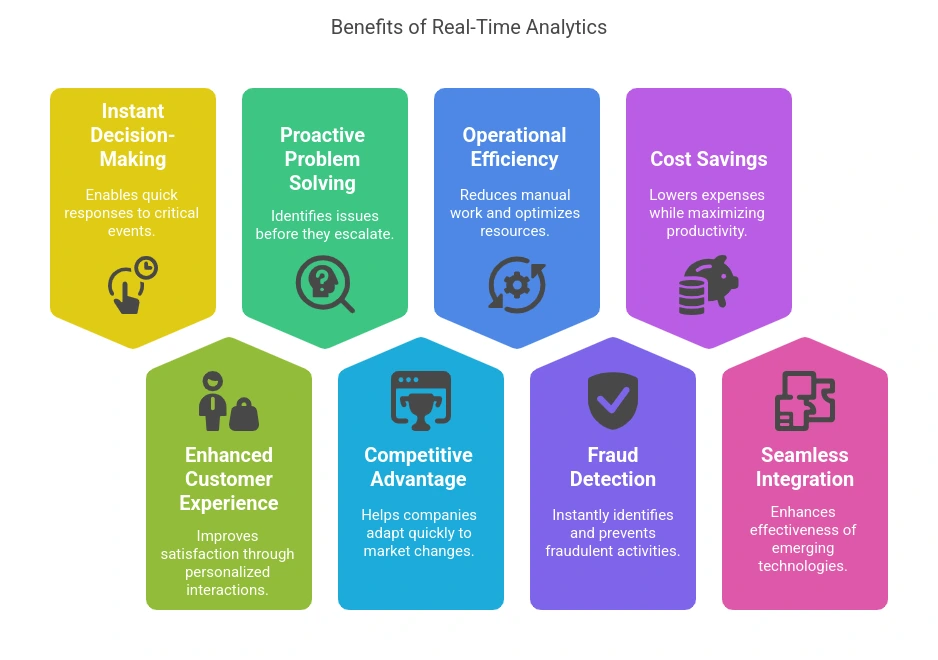
The best data pipeline tools offer real-time data processing for immediate, actionable insight that delivers more informed decision-making for better customer experience.
-
- Unstructured Data The data pipeline tool you choose should treat unstructured data (e.g., text, video, logs, etc.) as primary sources, rather than background noise. Not only do these data sources add an important holistic perspective to your data stack, they also can give teams advanced insight into market shifts and disruptions before they take hold in the marketplace.
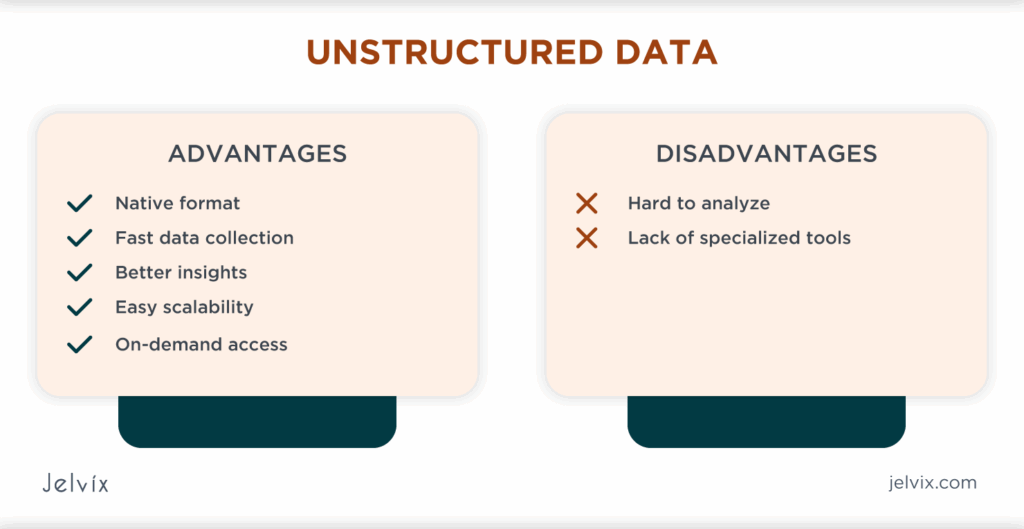
Fortunately, newer data pipeline tools like Dagflux are built to handle unstructured data in a way that makes it easy to analyze.
-
- Composable Data Stack A rigid data stack becomes useless almost as soon as it’s written. Composable data stacks are built from individual components that can be restructured, replaced, or scaled as needed.
Data in this format give teams ultimate flexibility, with faster time-to-insight, improved scalability, and the ability to experiment and hypothesize with their data.
Final Recommendations
ETL tools are non-negotiable for modern data-driven organizations. While many teams continue to rely on traditional data pipeline tools to help them manage analytics, AI-powered platforms like Dagflux are redefining the scope and capability of what these platforms can achieve.
Remember, there is no “one-size-fits-all” when it comes to modern data stack tools. The best tool for your team depends on its use case and the specific needs of your team. If you’re looking for the best data pipeline tool, it’s a good idea to start with a highly-scalable solution like Dagflux that’s easy to use, productive out of the box, and offers the ability to grow with your business.
FAQs
-
- What are data pipeline tools?
Data pipeline tools automate the extraction, transformation, and loading (ETL) of data from external sources to a centralized data repository (e.g. data warehouse, data lake, etc.).
-
- What is the difference between ETL and ELT?
The primary difference between ETL and ELT is the sequence of data movement.
In an ELT sequence, data is extracted from the source, loaded into a data repository, and then transformed — or formatted — in whatever ways have been directed by the user.
In an ETL sequence, data is extracted, transformed, and then loaded to the data warehouse.
There are other notable differences between the two processes.

Most teams opt for an ELT due to its low-maintenance structure and more affordable cost.
-
- Which data pipeline tool is best for startups?
Low-code and no-code platforms that leave plenty of room for scalability for growing teams (e.g., Dagflux, Stitch) are often the best choice for startups. These platforms give users the opportunity to hit the ground running with data analysis without heavy engineering support.
-
- Are there free data pipeline tools?
Technically, yes — but keep in mind that “free is just another price.” Apache Airflow, for example, has no cost to use but requires intense engineering resources that will cost your team time and expertise. You won’t pay for the platform, but you’ll pay in other ways.
Other tools, like Hevo and Fivetran, offer free tiers as part of their pricing structure for limited usage/features.
-
- What is the best tool for real-time data pipelines?
Some of the best real-time data pipelines in 2026 include Dagflux, Hevo, and Google Cloud Dataflow.