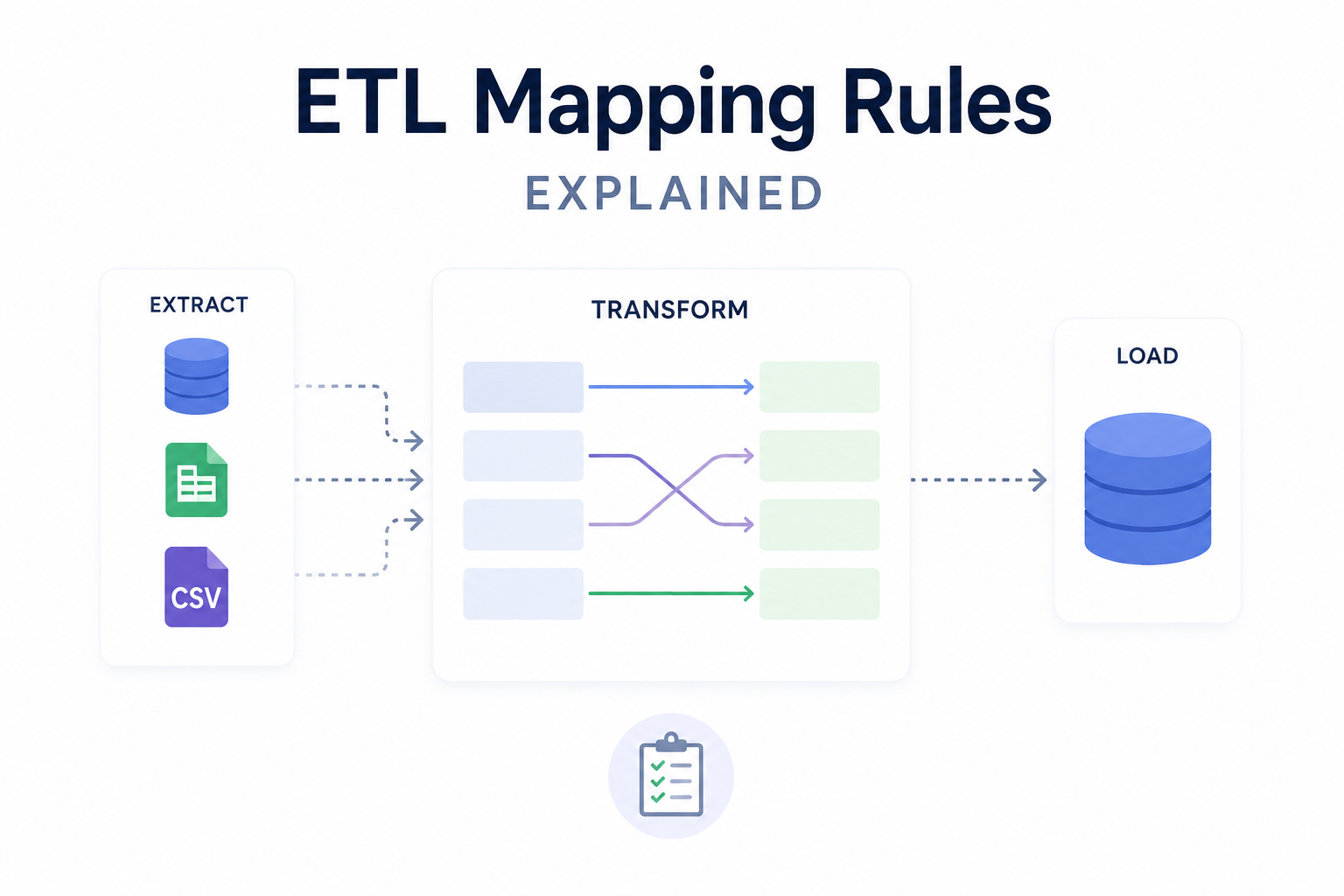
Every successful business relies on data to make informed decisions. In most cases, the challenge isn’t data access or availability; the issue is transforming raw data from external sources into usable formats within the target data system. To combat this, organizations rely on ETL mapping rules to align data fields between external data sources and their internal data system.
Data mapping rules help ensure that the ETL process runs smoothly, ensuring:
- Data accuracy across systems
- Consistency in formats and structures
- Reliable and scalable data migration between platforms
ETL mapping rules help mitigate the risk of data loss, redundancy, inconsistency, which can all lead to incorrect analytics that unknowingly undermine business decisions.
What Are ETL Mapping Rules?
ETL mapping rules define how data fields from a source system are transformed and loaded to a target system during the extract, transform, load (ETL) process.
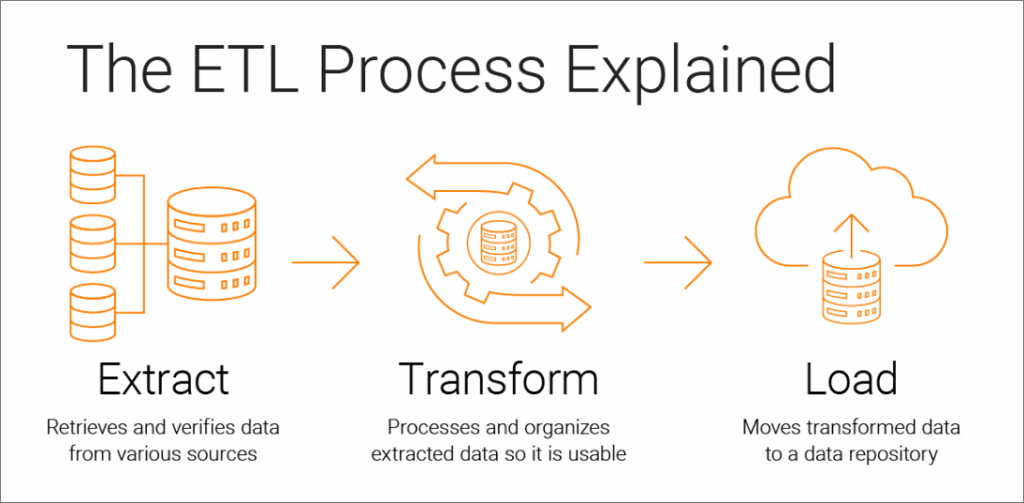
In many cases, data is defined differently within the source system than the target system. For example, a data source may define a field as “name,” whereas the target system may define that data as “first_name + last_name.” Data mapping rules provide specific instructions about how to define and translate the relationship between the source and target fields during the data transformation process, and how data should ultimately be loaded within the target system.
ETL mapping rules help ensure that any data that’s moved is accurate and consistent. If your data mapping rules are incorrect or nonexistent, the data your team relies on becomes unreliable. Risks of poor data mapping include:
- Data Loss Lack of ETL mapping rules, or poorly written rules, can cause data loss due to unmapped fields. The ETL process may filter out crucial data if there is no logic (via rules) behind the transformation.
- Inaccurate Data Data mapping rules help maintain the integrity of source data as it moves to your target system. Without them, transferred data could very well be inaccurate or incomplete.
- System Errors/ETL Failure Certain data formats or structures can create system errors during the ETL process.
Let’s take a look at some of the most common types of ETL mapping rules.
- Direct Mapping (Field-to-Field) Direct mapping rules represent a one-to-one connection in which the structure of the source field directly corresponds to a field in the target system. Direct mapping does not require any transformation or modification.
- Transformation Mapping Transformation mapping, on the other hand, does involve modification. It may require concatenation (e.g., “first name” and “last name” becomes “full name”) or calculation (e.g., price * quantity) of source data fields to match the target data structure.
- Conditional Mapping Conditional mapping rules rely on if/else logic. This type of rule transforms data based on specific criteria and allows systems to determine which action to take based on whether the criteria is met or not.
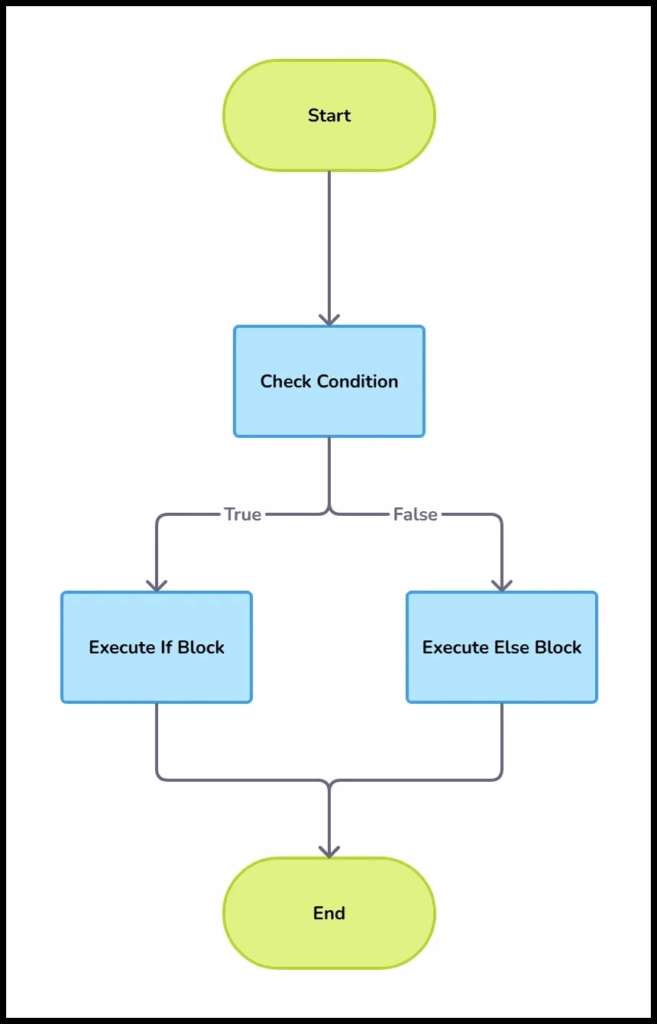
- Lookup Mapping Lookup mapping rules exist to enrich data or resolve discrepancies. They may dictate the need to reference or “look up” external databases to map source values to target values.
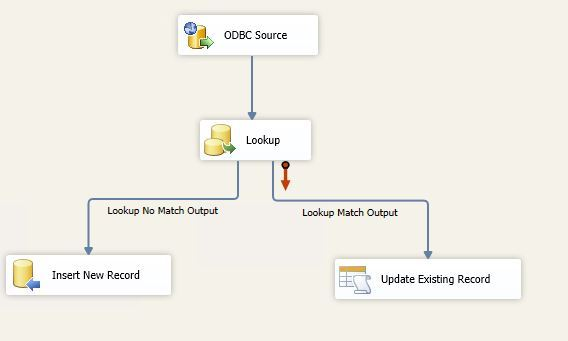
Every ETL transformation rule includes a few key components in order to be effective.
- Source Fields These originate from the source data system and contain raw data that’s ready to be extracted and mapped to the target data system (e.g., “customer_id”). This is sometimes called input data.
- Target Fields These represent the corresponding fields in the target data system, sometimes known as destination fields or columns (e.g., “client_id”).
- Transformation Logic This is the logic that transforms the source data and maps it into the target system (i.e., the rule that translates “customer_id” to “client_id”). Transformation logic exists on a spectrum from very simple (e.g., field-to-field) to highly complex (e.g., calculating averages, currency conversions). Transformation logic is the set of rules applied to the process.
- Data Types Common data types include strings, numbers, and dates. Good ETL mapping rules reference data types and how to convert them during transformation for effective mapping.
Just like any component of the ETL process, ETL mapping rules rely on specificity and explicit directives to be most effective.
ETL Mapping Rules Examples
Let’s take a look at five concrete examples of ETL mapping rules for real-world data pipelines.
- Direct Mapping
Remember, a direct mapping rule does not require any transformation.
Source: first_name
Target: first_name
This type of rule is used when no formatting changes are required. The field names already match, so data is copied as-is from source to target.
- Concatenation Rule
Here’s an example of a rule that does require some transformation.
Source: first_name + last_name
Target: full_name
This rule combines multiple fields or strings into a single field, creating a simple readable format for analytics reporting.
- Conditional Mapping
Let’s look at an ETL mapping example with a conditional rule.
If age > 18 → “Adult”
Else → “Minor”
A conditional rule is commonly used when you need to segment users.
- Data Type Transformation
Some ETL mapping rules help users transform data types into a single standardized format.
Source 1: “05/01/2026”
Source 2: “2026-05-01”
Source 3: “May 1, 2026”
Target: Date format “YYYY-MM-DD” → “2026-05-01”
This ETL rule mapping example standardizes the date format across source and target systems.
- Lookup Mapping
Let’s look at an example of a lookup mapping rule.
Source: country_code
Target: country_name
In this example, the ETL mapping rule transforms an obscure number assigned to a country into the actual country name (a much more usable format for reporting and analytics).
A lookup mapping rule is useful for enriching datasets with readable values.
Common ETL Mapping Techniques
In addition to ETL mapping rules, many teams also rely on specific ETL mapping techniques to improve data quality and streamline the process.
- Filtering Filtering data is the process of removing unnecessary data before loading it. This can help reduce storage costs and improve query performance and analytics.
- Aggregation Aggregation is the process of combining data (e.g., sum, average, count). This can help streamline multiple data points and present them in a usable format.
- Sorting When you sort data, try to do more than simply categorize it; instead, be specific in how you organize it so that you can maximize its value to your team.
- Splitting Fields Splitting data fields means breaking a single field into multiple components (e.g., full_name→first_name + last_name).
- Data Cleansing Cleansing your data might include fixing errors, addressing inconsistencies, removing duplicates, and standardizing formats. Effective data analysis relies on clean data.
These data mapping techniques will help your approach remain consistent, reliable, and scalable over time.
ETL Mapping Best Practices
Keep in mind the following best practices when you’re creating ETL mapping rules.
- Validate Source Data Even the most solid ETL mapping rules are defunct if the data you’re moving is invalid.

Always ensure that the data you’re moving is accurate and reliable so that you don’t move mistakes into your target data system.
- Document Mapping Logic You can make your ETL mapping rules scalable by documenting each rule and why it exists.
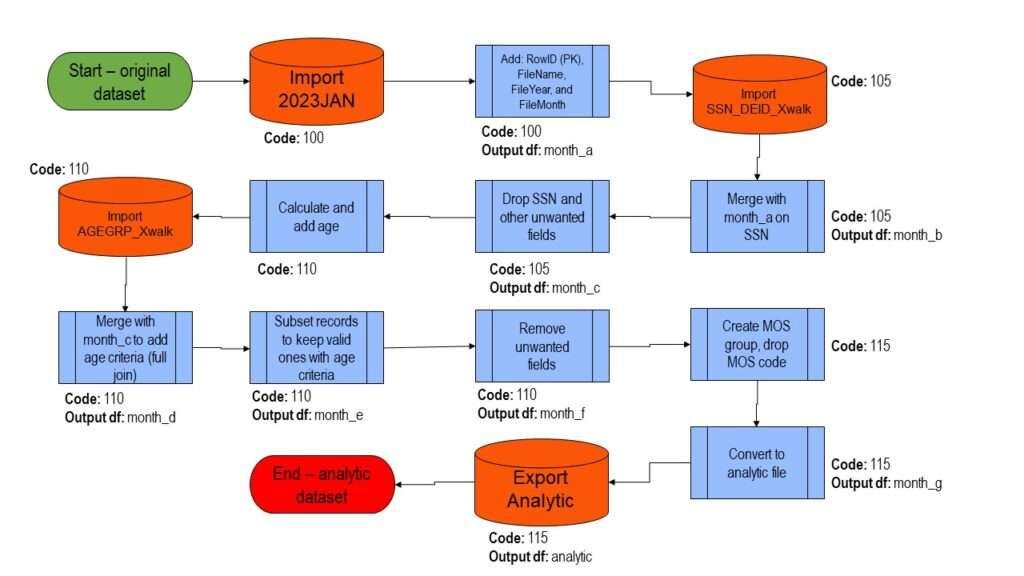
The more explicit your documentation process, the easier it is for your team to replicate, update, or correct your rules.
- Standardize Naming Conventions When it comes to ETL mapping rules, details matter — a lot. Data should be collected and moved in a standardized way, regardless of the source and target.
Even aspects as small as capital letters in a field name should be noted and standardized.
- Consider Null Values Null values can throw off the data mapping process if your team isn’t mindful of how to handle them. It’s crucial to define ETL mapping rules for missing or incomplete data to avoid errors or missing data.
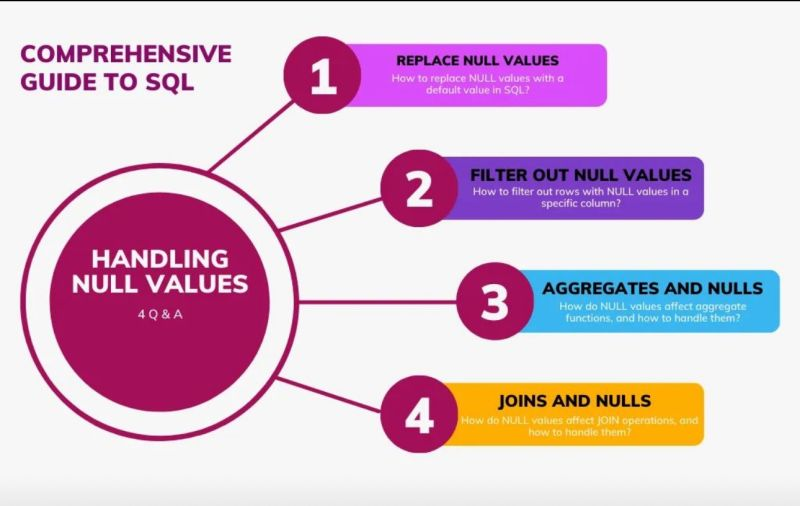
- Test Rules with Sample Datasets It’s important to test ETL mapping rules using simple, straightforward data, as well as complex and unusual datasets. Cover your bases during testing so you can catch issues early and ensure that your rules function correctly in every scenario.
- Automate When Possible Creating data mapping rules can be a repetitive process. Automation can help make the process more efficient and prevent errors that are prone to occurring with manual data entry.
- Use Version Control Part of documenting your mapping logic includes tracking changes in the process over time. Data schemas are liable to change as time goes on, and making note mapping shifts within each version will help ensure traceability and allow more leeway for changes if need be.
Adhering to these ETL mapping best practices can help ensure data reliability and scalability.
Common Challenges in ETL Mapping
The following challenges can create issues in data integration mapping. Keep an eye out for these as you fine-tune your process.
- Inconsistent Data Formats Each data system uses its own unique format for naming and storing data. Even seemingly straightforward data like date and name fields can have subtle differences in their structure, formats, or field labels. The solution? Standardize your data formats during transformation. If you don’t standardize data formats across systems before mapping to your target, you run the risk of moving incorrect data.
- Missing or Incomplete Data Some fields in the source system may contain null or partial values. To combat this, be sure to include ETL mapping rules that define fallback logic or default values.
- Complex Transformations It’s not uncommon for the data model of the source system to differ from that of the target system. These cases require complex transformations that rely on advanced logic or multiple steps, both of which can cause the process to go awry. To mitigate this issue, you can break down transformations into smaller steps. Many teams also rely on an ETL tool to help manage complex data scenarios.
- Performance Bottlenecks Scalability can be a real concern in ETL mapping due to the sheer volume of data. There is simply no feasible way for teams to keep up with the exponential growth of data available to them, and manual or even semi-automated data mapping can quickly create bottlenecks in the process. Take care to optimize your queries, use queries, and process data incrementally. Many teams also rely on AI or targeted ETL tools like Dagflux to help overcome this challenge.
- Schema Changes It’s normal for source or target data structures to evolve over time. These changes, however, can cause issues in the data mapping process. Use a flexible mapping approach and/or version control to mitigate these changes.
It’s not uncommon for teams to encounter challenges during data mapping. But adhering to the best practices outlined in this article can help your team know what to look for and find workarounds when issues do arise.
Tools That Support ETL Mapping
Many teams rely on tools to simplify their data mapping process; see below for a few examples.
- Talend
- Informatica
- Apache NiFi
- Microsoft SSIS
- Fivetran
These platforms offer features like:
- Visual drag-and-drop interfaces
- Prebuilt connectors
- Automated transformations
- Real-time and batch processing
A data mapping tool can help create efficient and reliable ETL mapping rules that your team can rely on across use cases.
Conclusion & Final Recommendations
Data mapping in ETL is essential to ensure accurate data integration from various sources into a unified target system. Organizations can ensure data accuracy, integrity, and efficiency by understanding the process and applying ETL best practices.
ETL mapping rules are the backbone of data pipelines. They ensure that the data within your target system is accurate so that your team can rely on it for meaningful insights and effective analytics and reporting. A subpar mapping process and/or a lack of ETL mapping rules can quickly cascade into costly data errors, including ineffective reporting.
Remember that there is no universal approach to ETL transformation rules. The “right” rules and data mapping process for your team depends on the structure of the data your team uses and your organization’s specific business goals.
FAQs
What are ETL mapping rules?
ETL mapping rules are instructions for extracting, transforming, and loading data from a source system to the target system. These rules dictate how fields from the source correlate to fields in the target system, including how to transform and handle specific data types during the ETL process.
What is data mapping in ETL?
Data mapping is the process of matching source data fields to their corresponding fields in the target system. This ensures that data is transferred accurately and consistently during the ETL process.
What are examples of ETL mapping rules?
Some examples of ETL mapping rules include direct (field-to-field) mapping, concatenation, conditional logic, lookup tables, and data conversion.
Why are ETL mapping rules important?
ETL mapping rules ensure data accuracy, consistency, and reliability. Risks of poor data mapping include data loss, duplication, or inaccuracies, which can lead to ineffective analysis for an ill-informed decision-making process.
Which tools are best for ETL mapping?
There are several tools available to assist with your data mapping process, including Talend, Informatica, Apache NiFi, Microsoft SSIS, and Fivetran. Look for tools that offer an intuitive visual interface, automation, and scalability.